Jekyll2024-10-03T20:20:02+00:00https://blog.martisak.se/atom.xmlMartin’s blogBlogging about the life as a PhD student with focus on reproducible research.Martin Isakssonmartin@martisak.seOur Research Recognized at 2023 IEEE Future Networks World Forum (FNWF)2023-11-15T00:00:00+00:002023-11-15T00:00:00+00:00https://blog.martisak.se/2023/11/15/fnwfWe are pleased to share some news from the 2023 IEEE Future Networks World Forum (FNWF) in Baltimore, MD, USA. Our paper, mmWave Beam Selection in Analog Beamforming Using Personalized Federated Learning was awarded the Best Paper Award. This recognition is both humbling and encouraging for us as researchers.
Best Paper Award ceremony at the IEEE FNWF banquet. Photo by Thomas Sandholm.
This achievement is not ours alone. It reflects the support and collaboration of many - from our colleagues and mentors to the broader community of researchers and professionals who continually inspire us. Our sincere thanks go to the IEEE FNWF for considering our work and to everyone involved in the conference.
A special mention to my co-authors Filippo Vannella, David Sandberg, and Rickard Cöster. Your insights and hard work were crucial in this endeavor. Working with you has been a rewarding experience. Toghether, we also extend our gratitude to all who contributed in various capacities, not least the coffee roasters who kept us going!
Congratulations to the other awardees. It’s an honor to be recognized alongside such talented peers.
For those interested, our paper is available here. We welcome your thoughts and engagement. Lastly, a thank you to Thomas Sandholm for capturing the pinnacle of our journey in this photograph.
We look forward to continuing our research and sharing our findings with the community.
]]>Martin Isakssonmartin@martisak.seOptimizing Your LaTeX Workflow: A Guide to Choosing a Build System2023-10-01T00:00:00+00:002023-10-01T00:00:00+00:00https://blog.martisak.se/2023/10/01/compilingLong LaTeX build times can be a significant challenge for researchers and
developers, hampering productivity and efficiency. This issue arises due to the
complexity of LaTeX documents and the diversity of build systems available. We
present a comprehensive exploration of LaTeX build systems, helping authors
choose the most suitable one. By identifying the best build system, authors can
streamline their workflow, reduce build times, and ultimately enhance their
research and development endeavors.
Introduction
I still remember the issues I had, many years ago, trying to build my Master
thesis report using latex and dvips. Since then
my build process has gone through a few iterations, to simplify, to make it
faster, or to accommodate some new thing that I learned. Frustrated by the long
build times, I have tried many things which may or may not have helped. The
discussion (for example Speeding up LaTeX
compilation)
seems to be plagued by hearsay. For a typesetting system that is used by
scientists, the discussion is unexpectedly remarkably unscientific.
In this blog post we will embark on an exploration of this rabbit hole,
unraveling the intricacies of different LaTeX build systems. We will dive deep
into the world of LaTeX compilation methods, comparing and contrasting different
local build methods. By the end, you’ll be equipped with the knowledge to choose
the right path for your next LaTeX adventure.
Background
Why don’t just use Overleaf?
Overleaf is fantastic, but a local LaTeX build environment can offer advantages over Overleaf in certain situations. A key benefit is control. With a local setup, users have complete control over their LaTeX distribution, packages, configuration and development environment. For me, the enhanced privacy and security is the most important reason to using a local build environment.
It is important to note that Overleaf excels in collaborative and cloud-based scenarios when teams working on LaTeX documents can work simultaneously in the same document. Overleaf allows real-time collaboration with version control and seamless sharing and also eliminates the need to install and manage LaTeX distributions and packages, making it accessible to users who may not be experienced installing complex software such as LaTeX.
Installing LaTeX
Your method of installing LaTeX varies with your operating system, the level of control you want, and other constraints. We will not go into this in detail here, see Getting LaTeX and Free TeX implementations.
Building a LaTeX document
LaTeX employs a multi-pass typesetting process to enable various features like table of contents, lists of figures, cross-referencing, glossaries, indexing, and bibliographic citations. In this process, the data generated during one pass (compilation) is saved to intermediate files and then serves as input for any subsequent passes.
The multi-pass typesetting process involves several steps to create a PDF
document with references using BibTeX and glossaries using makeglossaries:
Compilation with LaTeX. First we run pdflatex on the input .tex file.
This initial compilation generates an intermediate .aux file containing
information about citations, cross-references, and glossary entries. Since we
are using the package glossaries-extra, we also get a makeindex style
file .ist and an .acn file.
BibTeX for References If we have references in our document, we need to
run BibTeX on the .aux file. BibTeX reads our bibliography database
(.bib) and generates a .bbl file, which contains the formatted reference
information.
Glossaries with makeglossaries If we have a glossary in our document,
we use makeglossaries on the .aux file. makeglossaries reads the
glossary definitions and generates the necessary files to include glossary
entries in our document.
LaTeX Compilation (2nd Pass) Now we need to run pdflatex on the .tex
file again. This time, LaTeX incorporates the formatted references from the
.bbl file into our document. If there are any citations, they will be
correctly numbered and formatted in the reference list, but the citations
themselves will be rendered as [?].
LaTeX Compilation (3rd Pass) Running pdflatex on the .tex file once
more ensures that glossary entries are properly integrated into your document
and that citations are properly numbered.
Final compilations We need to repeat the pdflatex compilation step as
many times as needed to resolve all cross-references and ensure the document
is correctly formatted. LaTeX may issue warnings or errors during this
process that need to be addressed. In our case, for this document, we only
need to run pdflatex three times in total.
PDF Generation Once all the necessary information is integrated into your
document, a PDF file is generated as the output.
The example document we will use in the remainder of this post is based on the
IEEE conference
template(Shell, 2002). We will make some changes, for example adding a reference file
using BiBTeX and a glossary using the glossaries-extra package. We will also
add three example figures. These figures are available both in .eps and .pdf
format, so that we don’t need to run an expensive conversion process for each
figure. We will include these figures without the file suffix, for example
The third page contains the reference list and an acronym.
The last and fourth page contains the list of acronyms.
There are many things that effect the compilation times of a LaTeX document. See
What affects compilation times,
especially in longer
documents?.
The document we use here is short and doesn’t contain a lot of features, and we
do this to keep compilation times low since we will be repeating this build many
times.
To be able to compare the different methods, we will use a short timing script.
For each subdirectory it will run make clean test.pdf, 20 times each and
measure the time with /usr/bin/time. The different build methods fall into
different categories, see the following sections for a quick introduction to
each category.
Here’s a short summary of how to build a LaTeX document using the pdflatex, bibtex, and makeglossaries commands in the terminal
pdflatex test
bibtex test
makeglossaries test
pdflatex test
This is the classical method, used by hopefully very few people and is included here for completeness.
arara
Arara (Island of TeX, 2023) is a powerful and flexible build automation tool
specifically designed for compiling LaTeX documents. Developed as a
cross-platform solution, Arara simplifies the compilation process by allowing
users to define compilation sequences through a user-friendly configuration
file. With its intuitive YAML-based syntax, Arara lets you specify various
compilation steps, such as running pdflatex, bibtex, and makeglossaries,
in a defined order. This eliminates the need to remember and execute complex
command sequences manually. By offering a clear and structured approach to
compiling LaTeX documents, Arara enhances productivity and reduces the
likelihood of errors, making it an indispensable tool for LaTeX enthusiasts and
professionals alike.
latexmk
latexmk is a command-line tool designed to simplify the process of compiling
LaTeX documents. It automates the compilation workflow by intelligently handling
multiple runs of LaTeX and associated tools to ensure that all references,
citations, cross-references, glossaries, and bibliographies are resolved
correctly. latexmk is included in TeX Live. To customize the behavior of
latexmk we can use Perl-scripts, and here we give a short example of a
document specific configuration file that also includes makeglossaries.
rubber is a command-line tool designed to simplify the process of compiling LaTeX documents. Like latexmk, it automates the compilation workflow, aiming to provide a seamless and efficient way to handle LaTeX projects with various dependencies. We run this with the command rubber -d -m glossaries test.tex.
❯ pipenv run rubber-info test.tex
There was no error.
There is no undefined reference.
There is no warning.
There is no bad box.
scons
SCons is a Python-based Open Source build system that
simplifies the process of building and managing complex projects.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Make sure scons finds executables
importosenv=Environment(ENV=os.environ)# Target and source files
pdf_output=env.PDF(target='test.pdf',source='test.tex')# The Precious function is a method provided by SCons to mark a target
# as "precious" or "not to be deleted." This means that if SCons decides to
# delete temporary files or intermediate build artifacts after a build, it will
# not delete this particular target file even if it's considered an intermediate
# or temporary file.
# https://www.scons.org/doc/0.96.91/HTML/scons-user/c1924.html
env.Precious(pdf_output)
latexrun
latexrun is a Python-based build system designed to streamline the process of
compiling LaTeX documents. It aims to provide a comprehensive solution for
managing the compilation process and handling various dependencies.
The first part of your document, the preamble, changes must less often than the
body of the document. We can use this to our advantage by pre-compiling the
preamble. We need to split our file into a preamble, and a body part and
annotate each part properly.
The preamble should end with \endofdump.
1
2
3
% static part
...
\endofdump
We can compile this part with LaTeX in the following way
latex -ini -jobname="preamble" "&latex" mylatexformat.ltx "preamble.tex". This
will result in a file called preamble.fmt which we can reference in the body
of the document with
Mounting a directory as a RAM disk can significantly speed up tasks like LaTeX
compilation by using RAM for storage instead of the hard drive. Here we create a
small RAM disk that just fits our document. How to mount the ramdisk in practice
depends on your operating system and the details are therefore left to the
interesting reader to figure out.
Flags
In LaTeX, flags like batchmode and draftmode can help you optimize the
compilation process. Using batchmode suppresses most output, making the build
faster and less cluttered in the terminal. This is useful when you’re confident
your document is mostly error-free and want a quicker compile. The draftmode
flag, on the other hand, speeds up compilation by skipping the inclusion of
images and performing only minimal typesetting. This is great for quick previews
where fine details aren’t necessary, such as early steps in the compilation
process. Both flags can be added when running pdflatex or other LaTeX
compilers, like pdflatex -interaction=batchmode test.tex or pdflatex
-draftmode test.tex.
Dvips
In the early days of LaTeX, the standard workflow involved compiling the LaTeX
source code into a Device Independent (.dvi) file. This format was
platform-agnostic but not easily shareable or viewable. To produce a more
accessible Portable Document Format (.pdf), users had two primary routes:
Convert .dvi to PostScript (.ps) using dvips, and then convert the .ps file to .pdf using ps2pdf.
Use dvipdfm to directly convert the .dvi file to .pdf.
These methods were often cumbersome but necessary prior to the advent of pdfLaTeX, which allowed for direct compilation to .pdf files. We will include these older pipelines in our list of experiments to provide a more comprehensive view of the evolution of LaTeX.
Results
Build times
Our most important metric, and the one we set out to measure, is the build time.
Faster build times improve the efficiency of the document creation process,
allowing you to iterate more quickly through drafts. For those new to LaTeX, a
slow build process can be discouraging. Faster build times can make the learning
curve less steep. For me personally, long build times can interrupt my flow and
concentration, impacting overall productivity.
Build times
In this figure we can see that the fastest build system is preamble, where we
precompile the preamble using latex and compile the rest of the document with
latex+dvips+ps2pdf. This speeds up the build a lot! In fact, in the first half
of the list we see a lot of the same type of pipeline.
Manageable output
Human-understandable output, especially during errors, is crucial in LaTeX
document building. Most of the information printed however, isn’t very useful,
so it would make sense to try and reduce this and keep the output to a minimum.
In this test we simply count the number of lines on stdout, but it should be
said that some of these build systems, such as latexrun have really nice
colored output in the case things do go wrong.
Number of lines printed to stdout.
The first part of the list is dominated by build tools such as latexrun,
arara and rubber.
Ease of use
A build system must of course be easy to use, and as a proxy for that we measure
the number of characters in the Makefile target. In the case that you do use a
Makefile, simply running make would of course be easy enough.
Number of lines in the Maketarget
File size
A smaller file size offers advantages in terms of ease of handling, quicker
uploads, and efficient storage. Therefore, the file size serves as a crucial
parameter in evaluating performance.
PDF file size
It is interesting that there is such a big difference between the smallest and largest file size, even for such a simple document.
Final score
In the spirit of Eurovision and Melodifestivalen, we will adopt a point
allocation system that mirrors the excitement and competition of these iconic
music events. In Eurovision, each participating country awards points to their
favorite songs, with the famous ‘douze points’ (12 points) reserved for the top
choice. Similarly, the runner-up receives 10 points, acknowledging outstanding
performances, and we will continue this tradition here.
Total scores received.
The build system with the greatest final score is latexrun. We have seen how
we can improve the compilation time for a small toy project, but these
improvements carry over to real documents as well. For example, compiling a
recent IEEE paper using latexrun took 16.87 seconds compared to 25.71 seconds
using latexmk.
Related work
There are many general build systems such as Snakemake (Koster & Rahmann, 2012),
GNU Make, CMake, etc that can be used also to build LaTeX documents. There are
also many LaTeX specific build systems such as
make-latex,
AutoLaTeX and
ltx2any, that didn’t make it into this
comparison for one reason or another and I hope to return to them at a later
date.
In this blog post, we have strived to cover the most common build systems and
tool combinations for LaTeX document compilation. These systems have been chosen
based on their popularity and widespread use within the LaTeX community.
However, it’s important to recognize that the world of LaTeX is vast, and new
tools and approaches are continually emerging.
Therefore, one obvious limitation of this blog post is its inevitable inability
to encompass every possible LaTeX build system and tool combination. The LaTeX
ecosystem is dynamic, with developers and enthusiasts constantly devising
innovative ways to streamline the document creation process. As a result, there
may be niche or specialized tools that we have not explored here.
Some characteristics of a build system might be more important to you. For
example, the output from latexrun in the case of a fault is much easier to
read than for other build systems, and it leaves a build directory that is
almost clean. However, build directory cleanness is not measured in this blog
post.
Your choice of a LaTeX build system should of course be guided by your
individual preferences and workflow requirements. For example, when selecting a
build system, consider factors such as your operating system and LaTeX
distribution. Some tools are more compatible with specific platforms, and this
compatibility restricts what options are available to you.
Conclusion
In the realm of LaTeX document compilation, where efficiency and reliability are
paramount, one contender stands out as the victor – latexrun when precompiling
the preamble. Through our exploration of various build systems, including
latexmk, arara, SCons, and latexrun, it becomes clear that latexrun
in any of our variations stand out as a very good build system.
In the ever-evolving landscape of LaTeX document compilation, choosing the right
build system is a critical decision. While each contender we explored has its
strengths, latexrun emerges as the true champion, combining efficiency,
reproducibility, and versatility in a single package. As you embark on your
document creation journey, consider embracing latexrun as your reliable ally
in crafting elegant and polished documents, all while reclaiming precious time
and focus for what truly matters – your content.
]]>Martin Isakssonmartin@martisak.seTop LaTeX commands and macros for academic writing (and more)2023-08-11T00:00:00+00:002023-08-11T00:00:00+00:00https://blog.martisak.se/2023/08/11/top-latex-commandsLaTeX, a typesetting system celebrated for its capacity to effortlessly blend
visual appeal with practicality, remains an essential instrument for both
researchers and academics. While its inherent capabilities are impressive, the
full potential of LaTeX is revealed through the skillful utilization of its
macros. As a researcher in the field of artificial intelligence, I find that I
am very often using a set of LaTeX commands, macros and definitions when writing
academic papers, and perhaps you will find them useful too.
Introduction
In this blog post, we embark on a journey through the realm of LaTeX macros,
unveiling the ten eighteen most essential ones tailored specifically to
elevate your computer science paper writing endeavors. From effortlessly
formatting algorithms to seamlessly managing references, these macros are poised
to revolutionize your writing process, empowering you to focus more on your
content and less on formatting intricacies. Whether you’re a seasoned LaTeX user
or just beginning to explore its capabilities, this compilation promises to
enhance your efficiency, organization, and overall output in the domain of
computer science research.
In an earlier post we had a
look at ten LaTeX packages, but in this post we will look at commands and
macros. So, without further ado, and in no particular order, here are 10 18
useful LaTeX commands, macros and other tips for your writing pleasure.
Commands, macros and other tips
Math modes
When writing math in a paper, you can the LaTeX syntax \( x = 1 \) (or \[
for inline math mode (Wright, 2022). This will sometimes provide
better error messages, and having a begin and end point is nice if you ever
would like to parse the document with a script. The TeX
syntax $ x = 1 $ works as well, and some will say that this is more readable.
Read about other subtle differences at Are \ ( and \ ) preferable to dollar signs
for math
mode?
It is common that LaTeX introduces a line break inside the equation, which might
not look great for inline math. You can use curly brackets to avoid the line
breaking, for example \({ x = 1 }\).
Dynamic delimiters
Dynamic delimiters in LaTeX are great because they automatically adjust their size to match the content they enclose, ensuring optimal readability and aesthetic presentation of mathematical expressions.
You can manually vary the size of delimiters such as parentheses with \big(, \Big(,
\bigg( and \Bigg(.
\[( \bigl( \Bigl( \biggl( \Biggl(\]
However, almost always I use dynamically sized delimiters.
1
\left( \sqrt{a}+\sqrt{b}\right )^2
which produces
\[\left( \sqrt{a}+\sqrt{b} \right)^2\]
as opposed to
\[( \sqrt{a}+\sqrt{b} )^2\]
without using \left( and \right).
I recently learned we can do even better by declaring paired delimiters (Zeng, 2023)! By using the mathtools(Madsen et al., 2022) package we can define a paired braces with
1
\DeclarePairedDelimiter\braces{\lbrace}{\rbrace}
Then we can use the command \braces*{ ...} (note the starred version here) (Zeng, 2023).
siunitx(Wright, 2009) is a powerful tool for typesetting and formatting scientific and technical documents. It specializes in handling units, quantities, and numerical values, ensuring proper spacing, alignment, and consistent appearance.
1
2
3
4
5
6
7
8
9
10
11
12
\usepackage{siunitx}% SI unit setup\sisetup{
load-configurations = abbreviations,
binary-units = true,
exponent-product=\cdot}\DeclareSIUnit{\belmilliwatt}{Bm}\DeclareSIUnit{\dBm}{\deci\belmilliwatt}\DeclareSIUnit\px{px}
This allows us to add a number and unit with \SI{52}{\ampere\meter}. A number can be typeset with \num{1e5}. In an earlier post, we looked at using Pandas (pandas development team, 2020; Wes McKinney, 2010 ) to produce nice looking tables with no manual steps, and here we also used the table format S from siunitx.
Spaces and domains
Here are a few definitions of domains that I use.
1
2
3
4
5
\newcommand{\Z}{\mathbb{Z}}% Integer numbers\newcommand{\R}{\mathbb{R}}% Real numbers\newcommand{\N}{\mathbb{N}}% Natural numbers or prime numbers\newcommand{\C}{\mathbb{C}}% Complex numbers\newcommand{\Np}{\mathbb{N}^+}% Natural numbers including 0
For example \mathbb{N}^+ = \mathbb{N} \setminus \{0\} \(\mathbb{N}^+ = \mathbb{N} \setminus \{0\}\). To denote the empty set, I prefer $\varnothing \(\varnothing\) over \emptyset \(\emptyset\). For this, and many many more notations, see (Siek, n.d.).
Bachmann-Landau notations
Bachmann-Landau notation, a fundamental concept in theoretical computer science and mathematics, offers a concise and standardized way to describe the growth rates of functions and their relationships in mathematical analysis. Named after the mathematicians Paul Bachmann and Edmund Landau (Wikipedia contributors, 2023), this notation employs symbols like \(\mathcal{O}\), \(\Omega\), \(\Theta\), \(o\), \(\omega\) and \(\sim\) to articulate upper, lower, and tight bounds, on the behavior of functions as their inputs become sufficiently large. Bachmann-Landau notation provides a powerful tool for comparing algorithmic efficiencies, predicting performance, and understanding the scalability of mathematical models and algorithms.
Operators such as \(\sin\) and \(\cos\) are typeset in a roman font in math mode (Higham, n.d.)
. If you need to define a new operator, you can use amsmath to make sure spacing is consistent with the already defined operators.
1
2
3
4
5
6
7
8
9
10
11
\usepackage{amsmath}\DeclareMathOperator{\tr}{tr}\DeclareMathOperator*{\Max}{Max}\DeclareMathOperator{\Prob}{\mathcal{P}}\DeclareMathOperator{\sgn}{sgn}\DeclareMathOperator{\DFT}{DFT}\begin{displaymath}\Max_{x\in A} f(x) \qquad\End_R V
\end{displaymath}\def\diag{\mathop{\mathrm{diag}}}
Sometimes I see the notation := to denote a definition, and I don’t particularily care for it. I much prefer the overset triangle \triangleq \(\triangleq\) from amssymb.
If you’d rather use an overset text def, here is how to do that.
When I studied physics, my preferred way of writing vectors was using \vec{x} \(\vec{x}\). Nowadays, I prefer to use bold symbols for vectors and matrices using the bm package \bm{x} \(\bm{x}\).
Here is a controversial topic on which transpose sign to use. I prefer \intercal over T any day of the week, but I agree with the user @Heiko Oberdiek that it is typeset a little too low for capital symbols (such as matrices). For lowercase symbols, just using \intercal looks better to me. See the full discussion on What is the best symbol for vector/matrix transpose?.
I would like to have one macro for both lowercase and for uppercase symbols alike.
Overbrackets and underbrackets
Brackets, and braces, provide an excellent way of highlighting a part of an equation to be able to explain in better.
1
2
3
\begin{equation}\min_{\bm{w}\in\mathbb{R}^d}\mathcal{L}(w) \triangleq\min_{\bm{w}\in\mathbb{R}^d}\underbracket[.25pt][12pt]{\sum_{k=1}^K \frac{n_k}{n}\overbracket[.25pt][12pt]{\frac{1}{n_k}\sum_{i \in\mathcal{P}_k}\underbracket[.25pt][10pt]{\ell(\bm{x}_i, y_i, \bm{w})}_{\text{sample}\,i\,\text{loss}}}^{\text{client average loss}}}_{\text{population average loss}}\end{equation}
Under and over-brackets example
Inline TikZ
Sometimes it is easier to explain something with a small figure instead of creating some notation that is difficult to understand. I like to use this in a figure caption for example. We can use the tikz package (Feuersänger et al., 2014) for this.
\documentclass{IEEEtran}\usepackage{lipsum}\title{My IEEE article}\author{Author}\begin{document}\maketitle\global\csname @topnum\endcsname 0
\global\csname @botnum\endcsname 0
\begin{abstract}\lipsum[1]\end{abstract}\section{First Section}
As you can see in Fig~\ref{fig}\begin{figure}\centering\fbox{A nice figure}\caption{A nice figure}\label{fig}\end{figure}\lipsum[1-5]\end{document}
Without
With
IEEE references
When writing papers using the IEEE conference template(Shell, 2002) and BibTeX, you can use some
interesting trickery to automatically control when et al. will be written out (Shell, 2007) instead of editing the .bib-file. From the IEEE conference template we have that unless there are six authors or more we should print out the names of all the authors.
In the document itself, in the preamble, you need to add
Setting CTLuse_forced_etal to yestruncates the list of author names and forces the use of “et al.” if the number of authors in an entry exceeds a set limit.
CTLmax_names_forced_etal is the value of the maximum number of names that can be present beyond which “et al.” usage is forced. From the IEEE conference template we get that this shall be 6.
When et al. is forced, CTLnames_show_etal controls the number of names that are shown.
See (Shell, 2007) for complete list of parameters and default values.
Citations without line breaks
Citations and references is something that LaTeX and BibTeX do really well. A common way of citing is by writing word~\cite{source} so that there is a non-breaking space between the word and the brackets (assuming IEEE style here). However, when you cite multiple sources, the result is [7]–[9] or [10, 11] which could potetially introduce a line break within the citation itself! To fix this, we need to redefine the \citepunct and \citedash macros that determine what is inserted between the citations. In the first case, we just use a common non-breaking space ~, and in the second the \nolinebreak command prevents line breaking, and \hspace{0pt} allows the following text to start immediately, without inserting any additional space.
In academic writing, particularly in mathematics and related fields, the subtle nuances of notation play a crucial role in conveying precise meanings. This holds true for symbols like “epsilon,” often denoted as either \(\epsilon\) (lunate form) or \(\varepsilon\) (inverted-3 form). While both symbols might appear similar at first glance, they possess distinct roles in communicating mathematical ideas. Epsilon is commonly used as a placeholder for a small positive quantity in calculus and analysis, and is often employed when emphasizing a specific value within a sequence or as an arbitrary small quantity in proofs and formal arguments. The choice between these two symbols illustrates the meticulous attention to detail that characterizes academic writing, where even the slightest distinction can significantly impact the clarity and accuracy of mathematical expressions. Which symbol to use where might be a matter of discussion and source of confusion. See (Wikipedia contributors, 2023) and \varepsilon vs. \epsilon for more information on the two versions.
I like to use an upright \(\mathrm{i}\), as in (ISO, 2009). Adding a small kern to distance it from an exponent, we can define it as
1
\newcommand{\di}{\mathrm{i}\mkern1mu}% imaginary i in roman and with correct spacing
Bonus tip
Not a LaTeX command, package or macro, but an extremely useful tool - Detexify is a web-based tool designed to help users find the LaTeX command for a specific symbol by drawing it. There is also a Mac OS application!
Related work
There are a few other sites with similar lists, and here are some of my favorites.
In the world of LaTeX, a vast universe of tools and techniques awaits those who
wish to craft elegant mathematical documents. We’ve journeyed together through a
mere eighteen tips, each unlocking a new facet of the mathematical prowess of
LaTeX. From mastering different math modes to harnessing the power of dynamic
limiters, numbers, and units, we’ve delved deep into the intricacies of
mathematical typesetting. For anyone wishing to delve deeper into this, I would
recommend (Knuth et al., 1989).
As we conclude this exploration, we’re reminded that there’s no shortage of
LaTeX packages, macros or syntaxes, nor is there a lack of “top ten” lists
showcasing them. However, what truly matters is the journey you embark on with
LaTeX — a journey that enables you to bring forth your mathematical visions,
share your discoveries, and communicate the wonders of mathematics to the world.
So, whether you’re a seasoned LaTeX user or just beginning your mathematical
typesetting adventure, I hope these eighteen tips have been a source of inspiration
and knowledge. As you continue your LaTeX endeavors, remember that each
equation, each symbol, and each beautifully typeset equation is a testament to
the elegance and power of LaTeX. More importantly, the time you spend on
typesetting an equation is actually time spent on helping someone else
understand it. There’s a universe of mathematical expression waiting to be
explored, and LaTeX is your trusty spacecraft to navigate it. Here’s to your
mathematical journey, and I hope you’ve enjoyed this ride!
]]>Martin Isakssonmartin@martisak.sePublishing IEEE pre-prints2023-07-26T00:00:00+00:002023-07-26T00:00:00+00:00https://blog.martisak.se/2023/07/26/ieee-pre-printsIf you have submitted or plan to submit your paper to an IEEE journal or conference, you might want to consider posting your pre-print in arXiv.org or TechRxiv.org, on your employer’s website or institutional repository and on your personal website. IEEE does not consider this to be a form of prior publication, see IEEE Post-Publication Policies. But what are the practical steps to do so? In this post we cover the mandatory steps you have to take in order to publish an IEEE article as a pre-print.
Why is this important?
In the fast-paced world of scientific research, the dissemination of knowledge is crucial for advancing our understanding of the world around us. Traditionally, the process of scientific publishing has been slow and rigid, often resulting in significant delays between the completion of research and its availability to the wider community. However, a groundbreaking development has been reshaping the landscape of academic publishing – the rise of pre-prints. Pre-prints are early versions of research papers made publicly available before formal peer review, offering researchers the opportunity to share their findings rapidly and to get early feedback. It has been shown that papers with pre-prints have a citation edge (Conroy, 2019; Xie et al., 2021), and that this effect is clear, immediate and long-lasting.
Consider this first
Before you continue, please consult the author information for the conference or journal that you will or have submitted to. After making sure that you are permitted to publish a pre-print, then you have to follow the rules with regards to the information that needs to be put on the first page, see IEEE Post-Publication Policies(Post-Publication Policies, 2023). But how exactly do you do that? As usual in LaTeX, there are about a million ways, here is one that I like. Make sure you compile at least twice (which you already probably already do).
This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.
1
2
3
4
5
6
7
8
9
10
\usepackage{tikz}\newcommand\submittedtext{%\footnotesize This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.}\newcommand\submittednotice{%\begin{tikzpicture}[remember picture,overlay]
\node[anchor=south,yshift=10pt] at (current page.south) {\fbox{\parbox{\dimexpr0.65\textwidth-\fboxsep-\fboxrule\relax}{\submittedtext}}};
\end{tikzpicture}%}
\usepackage{tikz}\newcommand\copyrighttext{%\footnotesize\textcopyright\the\year{} IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, including reprinting/republishing this material for advertising or promotional purposes, collecting new collected works for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.}\newcommand\copyrightnotice{%\begin{tikzpicture}[remember picture,overlay]
\node[anchor=south,yshift=10pt] at (current page.south) {\fbox{\parbox{\dimexpr0.75\textwidth-\fboxsep-\fboxrule\relax}{\copyrighttext}}};
\end{tikzpicture}%}
Finally
On the first page (for example after \maketitle, add \copyrightnotice or \submittednotice as needed.
In case we want the box to be red and be 2pt wide we can of course do that.
1
2
\renewcommand\fbox{\fcolorbox{red}{white}}\setlength{\fboxrule}{2pt}% Set fbox rule width to 2pt
]]>Martin Isakssonmartin@martisak.seAdaptive Expert Models for Personalization in Federated Learning2022-06-11T00:00:00+00:002022-06-11T00:00:00+00:00https://blog.martisak.se/2022/06/11/moe-ifcaFederated Learning (FL) is a promising framework for distributed learning when
data is private and sensitive. However, the state-of-the-art solutions in this
framework are not optimal when data is heterogeneous and non-Independent and
Identically Distributed (non-IID). We propose a practical and robust approach
to personalization in FL that adjusts to heterogeneous and non-IID data by
balancing exploration and exploitation of several global models. To achieve our
aim of personalization, we use a Mixture of Experts (MoE) that learns to group
clients that are similar to each other, while using the global models more
efficiently. We show that our approach achieves an accuracy up to 29.78 % and
up to 4.38 % better compared to a local model in a pathological non-IID
setting, even though we tune our approach in the IID setting.]]>Martin Isakssonmartin@martisak.seAdding Sparklines to LaTeX tables using Pandas2021-10-23T00:00:00+00:002021-10-23T00:00:00+00:00https://blog.martisak.se/2021/10/23/sparklinesTables in scientific papers often look less than professional, and sometimes this can even get in the way of understanding the message. In this blog post we will learn how to add sparklines to a LaTeX table, which not only makes your table stand out, but also allows for conveying information about for example trends in time-series.
A sparkline is a very small chart, often in a text or in a table without axis or coordinates, that presents some measurement in an “intense, simple, wordlike graphics”. For example, The Dow Jones Industrial Average for February 7, 2006 (Licensed under CC BY-SA 2.5).
Example table using the Iris dataset from the `seaborn` library.
Sparklines are useful to show trends, highlight important events in time-series etc, which are otherwise hard to convey to a reader. They are especially useful
when there are many such time-series and a regular figure would take up too much valuable space. In this post we will add them to a LaTeX table, but they can be used in running text, in spreadsheets and in many other situations.
# First download the data from plotly's GitHub repository
df=pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/2016-weather-data-seattle.csv')df['month']=pd.to_datetime(df['Date']).dt.month# we define a dictionary with months that we'll use later
month_dict={1:'January',2:'February',3:'March',4:'April',5:'May',6:'June',7:'July',8:'August',9:'September',10:'October',11:'November',12:'December'}df=df.sort_values("month")df["datetime"]=pd.to_datetime(df.Date)df=df.drop(["Date"],axis=1)df=df.dropna()
Now we would like to group this data per month. Thereafter, we apply a magic function f.
Now that we have generated our table using Pandas, we need to include it in
our document. See table.tex, where the included includes/macros.tex contains some libraries and macros that we need, see macros.tex.
Most importantly, we load the sparklines LaTeX package (Löffler et al., 2017). We also need to define a new command for a rectangle that is defined by its left and right values.
1
2
3
4
5
6
\def\sparkrectangleh#1 #2 {%
\ifdim#1pt > #2pt
\errmessage{Theleftcorner#1 of rectangle cannot be lower than #2}%
\fi{\pgfmoveto{\pgforigin}\color{sparkrectanglecolor}%
\pgfrect[fill]{\pgfxy(#1, 0)}{\pgfxy(#2-#1,1)}}}%
Easily digested tables makes it easier to understand the idea and the message we are trying
to convey. In fact there is some
evidence (Huang, 2018) that the visual appearance of a paper is
important and that improving the paper gestalt reduces risk of getting a paper
rejected. In order to convey an idea efficiently we need to remove barriers so that the reader can understand this idea with as little cognitive effort as possible, and hopefully we have presented one way of achieving this here. We leave it to the reader to integrate this method into a Python package that is easy to use.
]]>Martin Isakssonmartin@martisak.seCreate publication ready tables with Pandas2021-04-10T00:00:00+00:002021-04-10T00:00:00+00:00https://blog.martisak.se/2021/04/10/publication_ready_tablesTables in scientific papers often look less than professional, and
sometimes this can even get in the way of understanding the message. In this
blog post we will use pandas to automate making
publication ready LaTeX tables that look great.
Introduction
Tufte argues that we should strive to have a high data to ink-ratio
(Tufte, 1986) which means that we should strive to remove redundant graphical element that do not contribute to conveying our message. This applies to tables as well.
For typesetting tables in my scientific papers I use
LaTeX with the booktabs(Fear, 2020) package. Using booktabs goes a long way towards
making beautiful tables with a high data to ink-ratio, but it’s a manual process.
Example figure produced with this method.
In this blog post we will explore using pandas(pandas development team, 2020; Wes McKinney, 2010 ) and booktabs for removing some
unwanted ink from our tables and building a pipeline for generating and including the tables into our LaTeX papers.
Using pandas to make a table
The first thing we need to do is to make a table from a dataset. We’ll look at
the Iris dataset (Fisher, 1936) from the seaborn(Waskom, 2021) Python library.
We could simply use the pandas function to_latex() to save a file containing the table in LaTeX format. pandas requires booktabs, but we can make this table even better with some simple tweaks.
Example table using the Iris dataset from the `seaborn` library.
First we want to specify the table column format and round the numbers to two decimals. Secondly, we want to highlight the maximum number in a column by making the numbers bold. And lastly, we want to make each column header bold.
Specifying the table format is easy using the siunitx package (Wright, 2009). We set each of the number columns to S[table-format = 2.2].
Making the maximum value in each column bold requires a bit more work. (Kalinke, 2020) wrote an inspiring post that we make use of here. Since we are using siunitx to specify the column format we use \bfseries to make numbers bold and allow siunitx to detect this by loading the package with \usepackage[round-mode=places,detect-weight=true,detect-inline-weight=math]{siunitx}.
Column header titles should be bold and in title case, so we directly modify df.columns to achieve this.
Since we added LaTeX tags to our table we must set escape to False in the to_latex call.
importseabornassnsimportosdefbold_extreme_values(data,data_max=-1):ifdata==data_max:return"\\bfseries %s"%datareturndataif__name__=="__main__":# Load data and
# calculate mean of each column
df=(sns.load_dataset('iris').groupby("species").mean().reset_index())# Specify in which columns to make the maximum bold
col_show_max=["sepal_length","sepal_width","petal_length","petal_width"]# Iterate through columns
forkincol_show_max:df[k]=df[k].apply(lambdadata:bold_extreme_values(data,data_max=df[k].max()))# Set column header to bold title case
df.columns=(df.columns.to_series().apply(lambdar:"\\textbf}".format(r.replace("_","").title())))# Write to file
withopen(os.path.splitext(os.path.basename(__file__))[0]+".tbl","w")asf:format="l"+ \
"@{\hskip 12pt}"+\
4*"S[table-format = 2.2]"f.write(df.head().to_latex(index=False,escape=False,column_format=format))
At the end we are using the pandas function to_latex() to generate the LaTeX code and write the result to a file containing the tabular environment. For this example, we have used seaborn==0.11.1 and pandas==1.2.3.
Now we are ready to include the generated file into a LaTeX document.
We want to create the file table.png. To do this we start with running
Python to generate the .tbl file that we then include in table.tex.
Compiling table.tex renders the table and saves it as a .png. We get
a .pdf for free when using pdflatex.
Related Work
(Kalinke, 2020) was the inspiration for this post. The method used herein to make numbers bold included code for formatting the numbers. In this work we use siunitx instead to do the formatting.
In R we can use packages xtable or kableExtra to achieve similar results. In particular, kableExtra is very capable and the documentation (Zhu, 2020) has many interesting examples.
The entire library of work by Edward Tufte is hugely inspirational to us.
(Tufte, 1986) tells us not to put too much ink on the paper.
Conclusion
We have looked at how to make tables generated by pandas to look more
professional by using siunitx and some tweaks. The Makefile we created
should go into the tables directory of your manuscript so that you can use
make -C tables all as a dependency to your normal make report target.
Easily digested tables makes it easier to understand the message we are trying
to convey. In fact there is some
evidence (Huang, 2018) that the visual appearance of a paper is
important and that improving the paper gestalt reduces risk of getting a paper
rejected.
]]>Martin Isakssonmartin@martisak.seBootstrapping your next LaTeX project2020-07-23T00:00:00+00:002020-07-23T00:00:00+00:00https://blog.martisak.se/2020/07/23/bootstrapping-your-next-latex-projectThe process of setting up a new LaTeX project is made up of many manual steps, resulting in a patchwork that already from the start is not exercisable nor complete. In this post we will see how we can construct a solid starting point with a single command. This is part of a series to create the perfect open science git repository.
Introduction
Setting up a new LaTeX project is usually a boring process where I do manual repetitive steps such as creating a directory structure, add file stubs, copy the Makefile from some old project, and more.
I like to use git for version control of LaTeX documents, so setting up a git repository is an important step. I do this even if I am working alone on a project. Version control allows me to track my progress, have a backup, and make sure the document is completely reproducible from raw data. The principle of
Reproducible Research(Buckheit & Donoho, 1995; Claerbout & Karrenbach, 1992; Association for Computing Machinery (ACM), n.d.) is to make data and computer code available for others to
analyze and criticize.
Add a README.md with some build instructions for my co-authors and
Perform a test compilation of the entire project.
Using a project template
What if we can run a single command to set up a new project? For this we can use [cookiecutter](https://github.com/cookiecutter/cookiecutter)(Roy Greenfeld et al., 2020). cookiecutter is a command-line utility that creates projects from cookiecutters which are project templates.
After you have run this cookiecutter template, you will have a working
directory that looks like this.
├── Gemfile # For the test stage
├── Gemfile.lock # For the test stage
├── Makefile # For building
├── README.md # A stub README
├── chapters
│ ├── conclusion.tex # A chapter in LaTeX
│ └── introduction.tex # A chapter in LaTeX
├── figures
│ ├── Makefile # A Makefile for building the figures
│ ├── example.py # Python code for plotting
│ └── requirements.txt # Requirements for the figure stage
├── lorem-ipsum.sublime-project # A Sublime project file
├── lorem-ipsum.tex # This is the main LaTeX file
├── references
│ └── main.bib # References in bibtex
└── spec
└── pdf_spec.rb # For the test stage
We see a lot of auxiliary files for testing and for setting up a Sublime project. If you have a better directory structure, feel free to fork my cookiecutter and make it better!
Related work
There are many existing cookiecutters for creating LaTeX documents. However, I didn’t find one that fitted my needs, so I made my own.
Yeoman(Osmani et al., 2020) provides another generator ecosystem, is language agnostic and can be used to generate any kind of scaffolding. However, since it is Node.js-based it could be argued that it is more geared towards web development. It is very extensible and it is easy to create custom templates, assuming knowledge of Node.js.
An interesting feature of Yeoman generators is that it allows for sub-generators. These can be used for example to generate new chapters in our documents.
Conclusion
So now we have a good starting point that you can use for your awesome next paper — all you need to do is fill in the blanks.
A remaining manual step is to find and copy the LaTeX template. If you always use the same template, this can be included in the cookiecutter template. In a future post we will look into how to use Pandoc and Markdown which will make choosing and switching templates easier.
]]>Martin Isakssonmartin@martisak.seLaTeX writing as a constrained non-convex optimization problem2020-06-06T00:00:00+00:002020-06-06T00:00:00+00:00https://blog.martisak.se/2020/06/06/latex-optimizerThe rejection rate for papers in good conferences is very high. To be accepted, a paper must not only be of a high scientific quality, but also at first impression perceived to be - or risk being thrown in the recycling bin. In this post we construct a system that automatically optimizes one proxy metric for perceived quality, removing one small frustrating step of scientific paper authorship and hopefully avoiding the bin.
Introduction
Scientific paper submission is a sort of empirical risk minimization problem where we want to minimize the risk that our paper will be rejected. We don’t have access to the true risk, but have to measure this empirical risk in some other way.
There are many factors that affect this risk - the most obvious being the quality of the content. However, with the increasing number of submissions the first impression of a reviewer is also increasingly important. In order for a reviewer to be able to assess the real quality of our paper, we must first avoid that the reviewer throws our paper into the recycling bin. A paper that successfully avoids the recycling bin should continue to convey a positive feeling so that the reviewer tries to find a reason to accept the paper rather than the opposite.
(Huang, 2018) trained a classifier to reject or accept a paper based solely on the visual appearance of a paper and found a few parameters that indicate good papers. One such interesting aspect is that we should fill all the available pages, which gives the impression of a more well-polished paper. In this post we will use this metric as a proxy for quality and minimize the empirical risk that our paper is rejected.
At submission time we find ourselves fighting the automated PDF checks of the publisher (see How to beat publisher PDF checks with LaTeX document unit testing) and we are changing figure sizes and other parameters, compiling and checking the output in order to fill the last page entirely and not have the content spill over to a new page. This process is frustrating, labor intensive, slow, and boring, not to mention error-prone.
The stuff from which nightmares are made - content spilling over to the fourth page.
A situation many of us recognize, regardless of where we are in our academic careers. With permission from "Piled Higher and Deeper" by Jorge Cham.
One large step towards a solution to this was proposed by (Acher et al., 2018) in which the authors annotate the LaTeX source with variability information. This information can be numerical values on figure sizes, or boolean values on options or whether to include certain paragraphs. In their work they formulate the learning problem as a constrained binary classification problem to classify into acceptable and non-acceptable configurations so that acceptable solutions can be presented to the user.
Here, we instead formulate this problem as a constrained optimization problem, where the constraints are defined by the automated PDF checks and the optimization is defined by proxy metrics such as amount of white space on the last page.
To find the optimal variable values we will use Ray Tune (Liaw et al., 2018). Ray Tune allows us to run parallel, distributed, LaTeX compilations and provides a large selection of search algorithms and schedulers.
Contributions
This work is inspired by three papers and develop these foundations in the following ways:
We again turn the example from the IEEE Manuscript Templates for Conference Proceedings to test these methods. The flushend package is used so that the last column is balanced. We also add another figure and vary each of the figure widths from zero width to one line widths - this will affect the amount of white space on the last page. A visualization of the last page white space can be seen in the figure below.
defcalculate_cost(self):pdf_document=fitz.open(self.pdffile)ifpdf_document.pageCount>3:return10000page1=pdf_document[-1]full_tree_y=IntervalTree()tree_y=IntervalTree()blks=page1.getTextBlocks()# Read text blocks of input page
# Calculate CropBox & displacement
disp=fitz.Rect(page1.CropBoxPosition,page1.CropBoxPosition)croprect=page1.rect+dispfull_tree_y.add(Interval(croprect[1],croprect[3]))forbinblks:# loop through the blocks
r=fitz.Rect(b[:4])# block rectangle
# add dislacement of original /CropBox
r+=disp_,y0,_,y1=rtree_y.add(Interval(y0,y1))tree_y.merge_overlaps()foriintree_y:full_tree_y.add(i)full_tree_y.split_overlaps()# For top and bottom margins, we only know they are the first and
# last elements in the list
full_tree_y_list=list(sorted(full_tree_y))_,bottom_margin= \
map(get_interval_width,full_tree_y_list[::len(full_tree_y_list)-1])returnbottom_margin
To calculate our metric it will be required to find the
dimensions of each page and each bounding box within the last page (Isaksson, 2020).
The basic algorithm is as follows: We loop over each
bounding box within the last page. For every bounding box we add an interval to
an interval tree for the dimensions in the y-direction. We can the use this to find the difference between the page dimensions and the extent of the bounding boxes on the page. For this we will use the Python package
intervaltree(Leib Halbert & Tretyakov, 2018).
For this example, we will vary the width of two figures, in terms of \linewidth. The value of each variable is sampled from \(\mathcal{U}\left(0,1\right)\).
Variable
Variable name
Type
Space
Unit
The width of Figure 1.
figonewidth
float
\(\mathcal{U}\left(0,1\right)\)
ratio of \linewidth
The width of Figure 2.
figonewidth
float
\(\mathcal{U}\left(0,1\right)\)
ratio of \linewidth
To make things easy for us, we write variable definitions to a macros.tex file and input this file in our LaTeX document preamble. The file contains for example the definitions for two figure width.
These variables are then used in the document to set each figure width individually. As an example, here is the first figure:
1
2
3
4
5
6
\begin{figure}[htbp]
\centering\includegraphics[width=\figonewidth\linewidth]{fig1.png}\caption{Example of a figure caption.}\label{fig1}\end{figure}
In this way we can avoid using a pre-processor, and we can use only LaTeX code in the document itself. Note that we do not specify the domain of these variables in the LaTeX-code, but define this in the Python-code instead, see Defining the experiment. In our work, these variables can be of any data type that is supported in LaTeX and Python.
Optimization problem
Our objective function is based on the last page bottom margin \(b(\boldsymbol{\theta})\) that is a function of our variables \(\boldsymbol{\theta} = \left[\theta_0, \ldots, \theta_n\right]\). We add a L2-regularization term on \(1-\theta_k\) for each variable \(\theta_k \in \boldsymbol{\theta}\) since we want to favor solutions with larger \(\theta_k\), solutions that have similar \(\theta_k\) and to make the math look more impressive. We negate the objective function and maximize it. If requirements set out in How to beat publisher PDF checks with LaTeX document unit testing are not met, we add a penalty to \(l(\boldsymbol{\theta})\).
The optimal variables \(\boldsymbol{\theta}*\) are then
As we can see in the figures below, the objective function \(l(\bf{\theta})\) is non-convex and the added L2-regularization gives us solutions that tend to have larger figure widths, which is what we want.
Our objective function depends on the two figure widths figonewidth and figonewidth.
The objective function with L2-regularization is more well-behaving, but note the lack of symmetry around the diagonal.
Note that we cannot tune the hyper-parameter \(\lambda\), so we set it to \(2\pi\), because that’s the most beautiful number known to man.
Hyperparameter search
Defining the tasks
We will use Ray Tune (Liaw et al., 2018) for searching this parameter space (the parameters we are defining here are of course not hyper-parameters). We begin with an exhaustive grid-search over the entire search space which is here \(v \in [0, 1]\, \forall \theta_k \in \boldsymbol{\theta}\). Since we have two figures each with a variable width we have \(\vert\boldsymbol{\theta}\vert = 2\). Performing a grid-search over each of the variables divided into 51 possible values gives us 2601 paper variants to compile. Each of the paper compilations consists of five steps;
Copy the LaTeX code to a temporary directory.
Sample variables and write to file macros.tex,
Clean document directory using latexmk and
Compile document with latexmk.
Measure quality proxy-metrics on PDF file.
The average execution time for each task is 5.46 seconds, and we can run 8 of these in parallel. This means that an experiment takes roughly 30 minutes on my laptop. With Ray Tune we also have the option to run this using a much larger set of machines if needed. Compilation using more than one CPU per worker is shorter, but since we can run fewer in parallel the total execution time is longer.
Document compilation (really Ray worker execution) time PDF, because measuring things makes it feel more like science.
Search algorithm
However, running an exhaustive grid search is not needed as we can use one of the search algorithms provided by Ray Tune instead. Specifically we will use a Asynchronous HyperBand scheduler with a HyperOpt search algorithm. HyperOpt (Bergstra et al., 2013) is a Python library for optimization over awkward search spaces. In our use-case we have real-valued, discrete and conditional variables so this library works for us, but we will not evaluate its performance on our objective function and can therefore not claim that it is the best search algorithm for this particular problem.
Defining the experiment
We define our experiment directly in the code, for simplicity. First we will define our search space. Here we sample each variable from \(\mathcal{U}(0,1)\).
Visualizing LaTeX compilation metrics via Ray Tune using Tensorboard in Docker ticks all the nerd-boxes.
Ray Tune integrates well with MLFlow. Here we use the Parallel Coordinates Plot to visualize invalid solutions.
The Ray dashboard provides a minimal dashboard to monitor the workers.
MLFlow (Databricks, 2020) is a Python package that can be used to for example track experiments and models. Here we use it to visualize the hyper-parameters and the corresponding objective function score. The MLFLow UI can be started simply with mlflow ui.
Solutions found
The objective function with L2-regularization visualized with solutions searched by HyperOpt.
Objective function score as a function of figure widths when both figures are set to equal width. Note that the optimal solution is not the maximum figure width that still satisfies the constraints.
For the specific objective function illustrated here, we could potentially use a variant of gradient descent. However, as we add more variables, the search space becomes more complicated.
Using Ray Tune has a major advantage in that it is easy to parallelize our document compilation on a large set of workers and the API makes changing scheduler and search algorithm a breeze.
Related work
In the inspiring “VaryLaTeX: Learning Paper Variants That Meet Constraints” paper (Acher et al., 2018) the authors annotate LaTeX source with variability information and construct a binary classification problem where the aim is to classify a configuration as fulfilling the constraints or not. The classifier can be used to present a set of configurations to the user that then can pick an aesthetically pleasing configuration out of the presented set. This is a much more complete solution that the one presented in this post. A potentially interesting addition to their work is to annotate the configurations with a score, that can be used to sort a potentially large set of valid configurations. See their Github repository.
(Huang, 2018) constructs a binary classification tasks to predict if a paper is good or bad, based on the Paper Gestalt of a paper, i.e. only the visual representation of the paper. The paper goes on to discuss how to improve the Paper Gestalt, for example adding a teaser figure, a figure on the last page and filling the complete last page. The latter can be numerically estimated, which is what we based this blog post on.
Limitations, discussions and future work
The experiments in this blog post aim to produce a single paper that fulfills all publisher constrains and requirements. This single paper is optimized in terms of last page white space, which disregards pretty much everything that makes a paper great and should therefore be used with caution.
There are other metrics that we can use for optimization, for example the number of words, data density (Tufte, 1986). We can add more variability by considering figure placement, microtype options (Schlicht, 2019), and more.
In this post we viewed the parameters as hyper-parameter and used Ray Tune, which is made for tuning hyper-parameters . The parameters we used are in fact not hyper-parameters, and other frameworks and solvers could have been used. However, we find that two aspects of Ray Tune makes it a good candidate for this problem; it’s is simple to use and it can parallelize these tasks efficiently.
Conclusions
While the last page white space is obviously a bad proxy for paper quality, we have shown that we can remove a part of paper writing that is labor intensive, slow, boring, and error-prone. We combined three pieces of work that I find ingenious in their own rights to make a complicated machine to optimize a parameter that maybe doesn’t matter all that much - but, hey, it was fun!
]]>Martin Isakssonmartin@martisak.seHow to beat publisher PDF checks with LaTeX document unit testing2020-05-16T00:00:00+00:002020-05-16T00:00:00+00:00https://blog.martisak.se/2020/05/16/latex-test-casesWhen submitting a scientific paper to a conference or a journal, there is
often a mandatory step of passing the automated PDF checks set up by that
publication. This step can often be nerve-racking and cause many hours of
LaTeX troubleshooting. In this post we will create a series of test cases to
catch these problems early in the writing process so that you can submit your
manuscript only once.
Introduction
Recently, I submitted a
scientific paper to an IEEE conference. For a manuscript to be accepted by
the publishing system
Editor's Assistant (EDAS)
it has to pass an unknown number of unspecified test cases. This took far too
many attempts, as can be seen in the figure to the right.
Here is one error that I received.
The gutter between columns is 0.165 inches wide (on
page 3), but should be at least 0.2 inches.
Nowhere did it say that the gutter should be 0.2 inches. Another IEEE
conference that I submitted to had a smallest gutter width of 0.16 inches,
and it seems that this is up to each
conference chair to decide. As you can imagine, when trying to fix this,
some text will spill over to the next page so then the document is over the
page-limit. Uploading a document many times is a pain.
In this post we will create a series of test cases to catch these errors
locally before submitting.
The publishing system gave this message for the final version of the
manuscript that was uploaded without problems.
The paper has 6 pages, has a paper size of 8.5x11 in (letter), is
formatted in 2 columns, with a gutter of 0.201 inches (smallest on pg. 5), the
most common font size is 9.96 pt, the average line spacing is 11.95 pt, margins
are 0.673 (L) x 0.653 (R) x 0.701 (T) x 0.990 (B) inches, uses PDF version 1.7
and was created by TeX.
It can take many attempts to pass EDAS PDF checks.
Template
The techniques we use here can of course be applied to any PDF document. We will
here take a look at a two-column conference paper since this provides us with a
number of interesting things to test that other formats don’t.
The IEEE Manuscript Templates for Conference Proceedings example is particularly interesting due to the multiple author bounding boxes. We can download the template and an example document and compile it directly to produce the PDF that we will run our test cases on.
Test cases
Requirements and setup
We need to understand the requirements of the publishing system. Some of these
requirements can be found on the conference website. For example, we see that
the page limit is 6 pages in a 10 point font, and that we should use the IEEE
Manuscript Templates for Conference Proceedings
template. Other
than that, there is no more useful information.
Here are the requirements, gathered from various sources, that we are going to
write test cases for in this post.
Some of them, for example the margins are tweaked after a paper that passed the
test had margins narrower than the one suggested by the IEEE requirements.
It would be a bit embarrassing to submit a file with annotations still in it, so
let’s start by checking that we didn’t add any.
1
2
3
4
5
6
7
8
deftest_annotations(pdf_document):"""
Test that there are no annotations.
"""forpage1inpdf_document:annotations=list(page1.annots())assertnotannotations
Metadata
For the metadata fields creator, producer, author, title, subject,
encryption and keywords we can simply check that the result is as expected by
comparing to what we defined in the configuration file config.yml.
1
2
3
4
5
6
7
8
9
10
11
12
13
deftest_metadata(pdf_document,config):"""
For each of the specified fields, check that the result
is as expected.
"""metadata_fields=["author","creator","title","subject","keywords","producer","encryption"]forfieldinmetadata_fields:assertpdf_document.metadata.get(field,None)==config["metadata"].get(field,None)
For the PDF version, we usually specify a minimum version so we define a
separate test case for that. Should we need to change this in the document, we
can add
\pdfminorversion=7
to our preamble.
1
2
3
4
5
6
7
8
deftest_pdf_version(pdf_document,config):"""
Test that the PDF version is at least the specified
"""version=float(pdf_document.metadata.get("format",None).split("")[1])assertversion>=config.get("min_version",1.4)
Number of pages
It is quite common that a conference and a journal has a maximum number of
pages. The lowest number of pages is of course one, but we’d most likely want to
use every inch of space available to us.
1
2
3
4
5
6
7
8
9
deftest_pages(pdf_document,config):"""
Test that the number of pages is between
the minimum and the maximum number of pages.
"""assertconfig.get("min_pages",1)<= \
pdf_document.pageCount<= \
config.get("max_pages",5)
Dimensions
To calculate margins and other dimensions it will be required to find the
dimensions of each page and each bounding box
within each page. In the process we also find the number of columns.
The basic algorithm is as follows: We first loop through each page and each
bounding box within that page. For every bounding box we add an interval to
an interval tree -
one for the dimensions in the x-direction, and one for the dimensions in the
y-direction. For this we will use the Python package
intervaltree(Leib Halbert & Tretyakov, 2018).
Interval trees(contributors, 2020) are interesting in their own right, but we won’t go into
the details of how they work. Here it is enough to say that we can do
operations on these interval trees to find the widths of gutters and margins
easily.
For each new bounding box we find, we add the interval between the left edge and
the right edge to one interval tree. After we have done this for all bounding
boxes we merge the overlap of these intervals so that we are left with a list of
non-overlapping intervals. We do this both for the x-dimension (illustrated
below in blue) and the y-dimension (illustrated below in red).
The first page with overlayed non-overlapping bounding boxes in the x-direction in blue and non-overlapping bounding boxes in the y-direction in red. To find the two columns, the 12 first bounding boxes were skipped.
The second page with overlayed non-overlapping bounding boxes in blue. There is only one non-overlapping bounding box in the y-direction.
The first and the second page illustrate how complicated the bounding box analysis can be.
We see that the first page contains things like the title and author blocks that
straddle the gutter. This will affect how we can detect the columns and
calculate the width of the gutter. Here, we take an easy way out and just skip
the first 12 bounding boxes. We find the number of bounding boxes to skip by
counting the red boxes in the figure. This problem also extends to pages where a
top figure spans the two columns.
After we have calculated the non-overlapping intervals we can easily calculate
the width of these. For a two column document, the first interval is the left
margin, the second is the first column and the third interval is the gutter.
Since the margin and gutter is different on each page, we assert that all of
them meet the requiements.
Should the gutter be too narrow (something that always happens way too often)
we can tweak the column separation with
1
\setlength{\columnsep}{0.235in}
Another thing that will effect this is microtype and it’s various options,
for example protrusion.
deftest_dimensions(pdf_document,config):"""
This test case loops through pages and checks
- paper size
- gutter width
- number of columns
Finally it saves a document with the found columns and bounding boxes
overlayed.
"""blue=(0,0,1)count=0forpage1inpdf_document:full_tree_x=IntervalTree()full_tree_y=IntervalTree()tree_x=IntervalTree()tree_y=IntervalTree()blks=page1.getTextBlocks()# Read text blocks of input page
img=page1.newShape()# Prepare contents object
# Calculate CropBox & displacement
disp=fitz.Rect(page1.CropBoxPosition,page1.CropBoxPosition)croprect=page1.rect+dispfull_tree_x.add(Interval(croprect[0],croprect[2]))full_tree_y.add(Interval(croprect[1],croprect[3]))# This tests paper size
assertlist(croprect)==config["pages"].get("papersize")forbinblks:# loop through the blocks
r=fitz.Rect(b[:4])# block rectangle
# add dislacement of original /CropBox
r+=dispx0,y0,x1,y1=r# Dangerous!
ifcount>config.get("skip_boxes_on_first_page",2):tree_x.add(Interval(x0,x1))tree_y.add(Interval(y0,y1))count+=1tree_x.merge_overlaps()tree_y.merge_overlaps()# Must be two columns
assertlen(tree_x)==2forintrvintree_x:a=[intrv[0],tree_y.begin(),intrv[1],tree_y.end()]re=fitz.Rect(a)img.drawRect(re)img.finish(width=1,color=blue)img.commit(overlay=True)# store /Contents of out page
foriintree_x:full_tree_x.add(i)full_tree_x.split_overlaps()foriintree_y:full_tree_y.add(i)full_tree_y.split_overlaps()# If there are two columns, the gutter should be in the middle.
# Margins are the first and last intervals, the ignored parts
# are the left and right columns.
left_margin,_,gutter,_,right_margin= \
map(get_interval_width,list(sorted(full_tree_x)))# For top and bottom margins, we only know they are the first and
# last elements in the list
full_tree_y_list=list(sorted(full_tree_y))top_margin,bottom_margin= \
map(get_interval_width,full_tree_y_list[::len(full_tree_y_list)-1])assertgutter>config["margins"].get("min_gutter",0.2)assertleft_margin>config["margins"].get("min_lr_margin",0.625)assertright_margin>config["margins"].get("min_lr_margin",0.625)asserttop_margin>config["margins"].get("min_top_margin",0.75)assertbottom_margin>config["margins"].get("min_bottom_margin",1)# save output file
pdf_document.save("layout.pdf",garbage=4,deflate=True,clean=True)
Links and bookmarks
Links and bookmarks are created by hyperref. I’d like to keep this package, but set the output to draft for the final publication in order to disable it.
1
2
3
4
\usepackage[
final,
bookmarks=true
]{hyperref}
Testing that we have not links or bookmarks in our document is simple, we just
make sure that the list of links on each page is empty and that the bookmark
list is empty.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
deftest_no_links(pdf_document):"""
Test that no links appear on any page.
"""forpage1inpdf_document:assertlen(page1.getLinks())==0deftest_no_bookmarks(pdf_document):"""
Test that the document does not contain bookmarks
"""assertlen(pdf_document.getToC())==0
File size
The system that we upload our document to has a limit on the size of document, and it is easy to test for this.
1
2
3
4
5
6
deftest_file_size(pdf,config):"""
Test that the filesize is below the limit.
"""assertPath(pdf).stat().st_size<config.get("max_file_size",0)
Spelling and grammar
To test spelling and grammar I use LanguageTool, textidote and vale. However, the number of false positives are staggering and they are unusable for automatic testing. This is also a larger topic that deserves an in-depth analysis.
Title in title case
The title shall be in title case. In this regard EDAS follows the Associated Press Stylebook and the New York Times style book. These state that only short prepositions and articles with four letters or less are lowercase.
The Python package titlecase uses a wordlist from New York Times Manual of Style to decide what words shall be lowercase.
1
2
3
4
5
6
7
8
9
deftest_title_case(pdf_document):"""
Test that the title (first block on first page)
is title cased properly.
"""page1=pdf_document.loadPage(0)title=page1.getTextBlocks()[0][4]asserttitle==titlecase(title)
Required text
For my work I am required to put in a pre-defined sentence in the
acknowledgment-section so I want to test that the document contains this string.
This test case can easily be modified to detect black-listed words.
1
2
3
4
5
6
7
8
9
10
11
deftest_required_text(pdf_document,config):"""
Test that each required text is found in the document.
"""fortextinconfig.get("required_text",[]):hits=0forpage1inpdf_document:hits+=len(page1.getTextPage().search(text))asserthits>0
Embedded fonts
We can test that the fonts are embedded by trying to extract them from each page.
This can be optimized since each font will be extracted several times. At the same time
we will check that the font is not a
Postscript Type 3 font, since these can be
bitmap fonts. This can for example happen when using matplotlib since
matplotlib will use Type 3 fonts per default. See (Oaks, 2014) or
Publication ready figures
for ways to get around this.
1
2
3
4
5
6
7
8
9
10
11
deftest_embedded_fonts(pdf_document):"""
Check that all fonts are extractable. This will at least loop through
the embedded fonts and check their types.
"""forpageinpdf_document:forfinpage.getFontList():_,ext,fonttype,_=pdf_document.extractFont(f[0])assertfonttypein["TrueType","Type1"]assertext!="n/a"
Results of the test cases
We can compile the example document and run our test suite with
1
2
make -C example dist-clean compile
pytest -v--pdf example/Conference-LaTeX-template_10-17-19/conference_101719.pdf
This is the same as running make render test (using Docker containers),
which gives us these results.
There are many test frameworks and PDF readers that could have been used instead
of pytest and pyMuPDF. In the past I have used rspec with pdf/reader
which is easy to get started with, but since I am more familiar with Python I
opted for that when it came to more advanced tests.
There are a few common mistakes that we didn’t create test cases for. The
required font sizes is listed by (Shell, 2002), but hard to test for
since figures and titles can have wildly different font sizes. Line-spacing is
similar to font-size in this regard.
Other common mistakes, such as not referencing a figure in the text is better
suited for linting tools such as textidote.
Conclusions
In this post we have implemented a few test cases to detect common mistakes in
IEEE conference submission - before the conference PDF checker catches them.
I hope that this saves you some frustration, and some time.


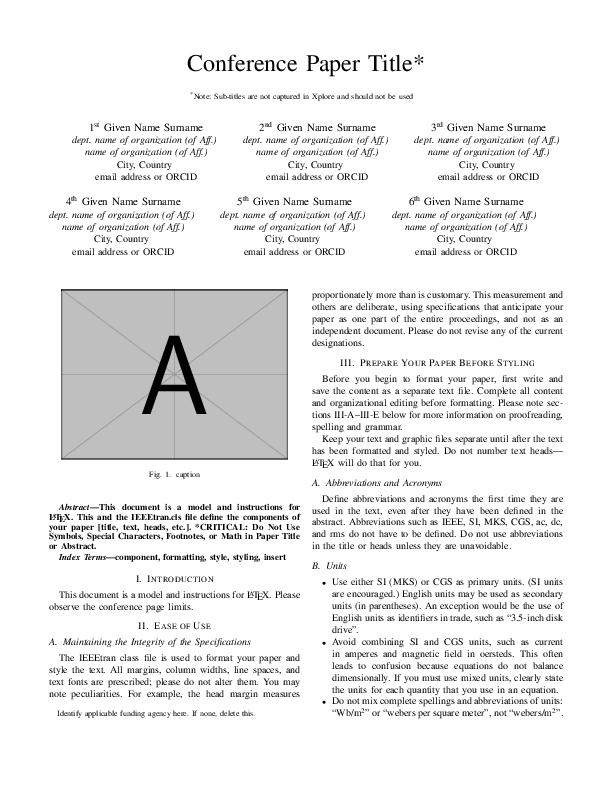







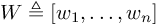
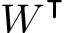
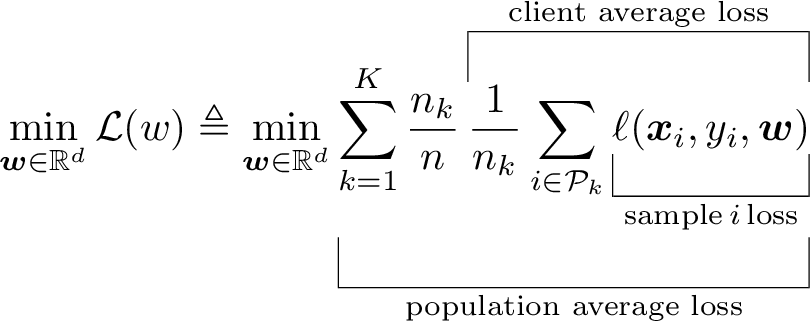



 (Licensed under
(Licensed under 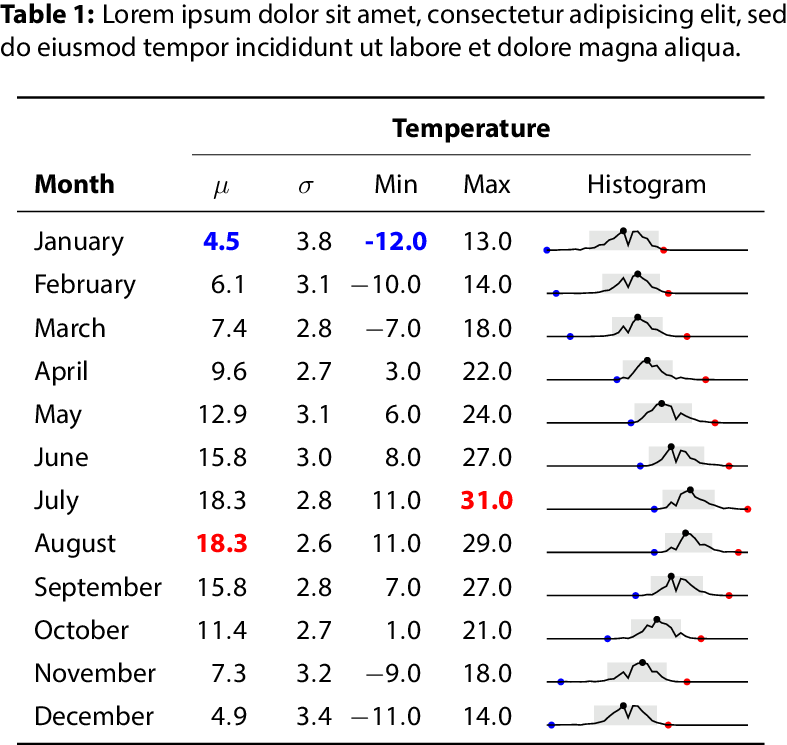
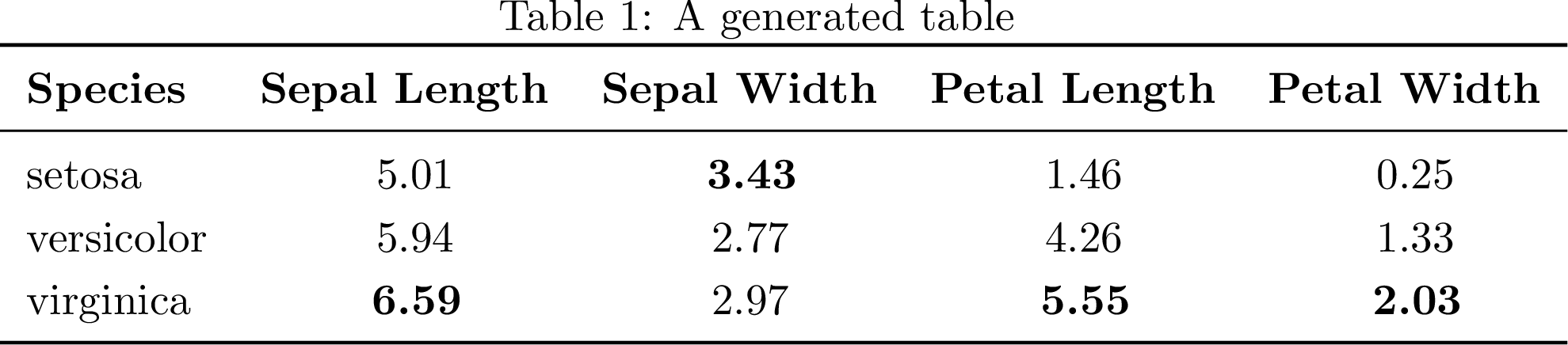
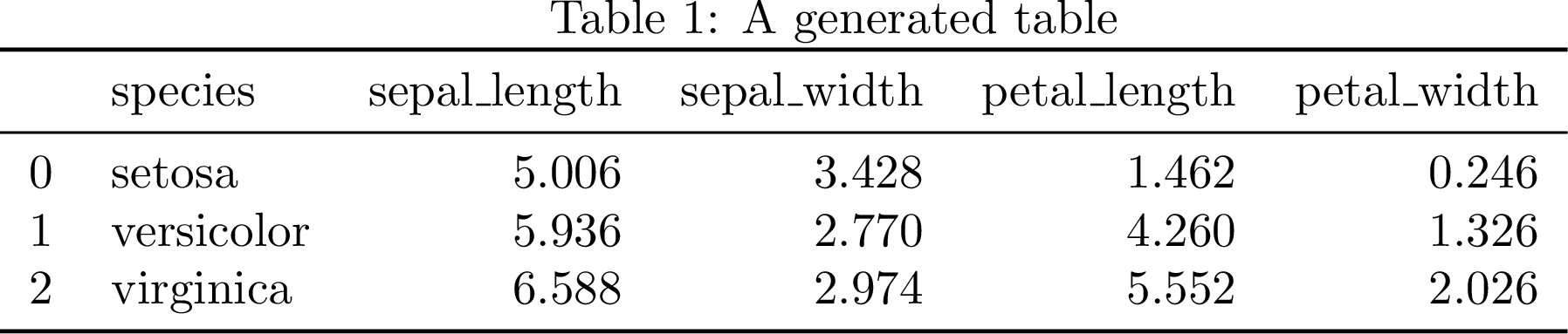







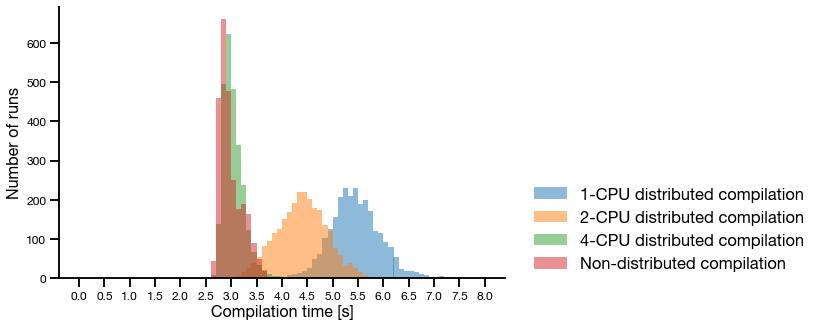
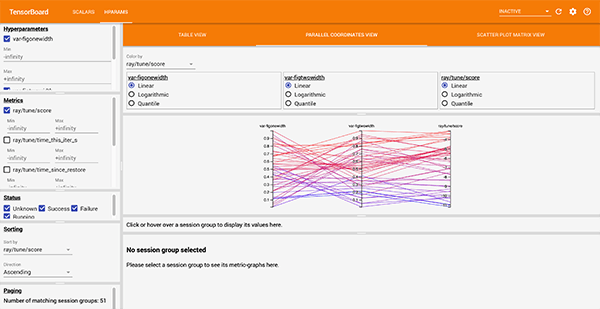
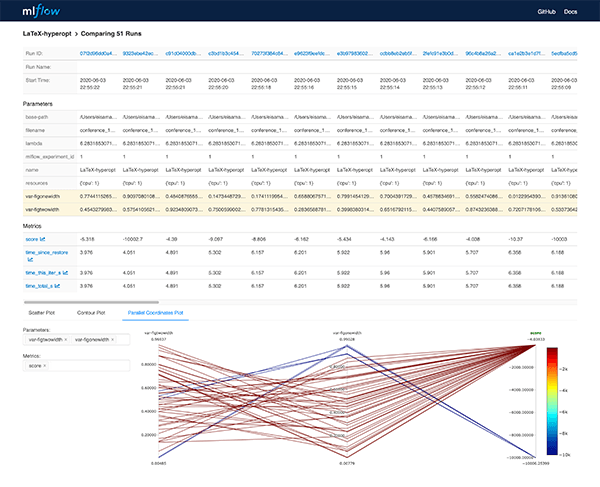
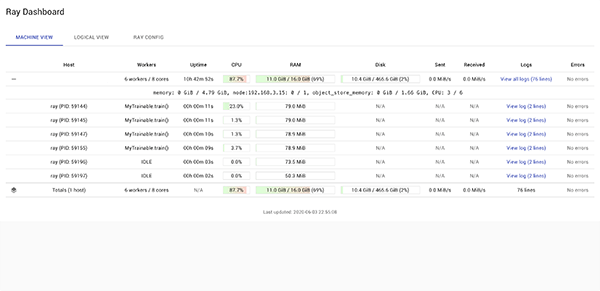
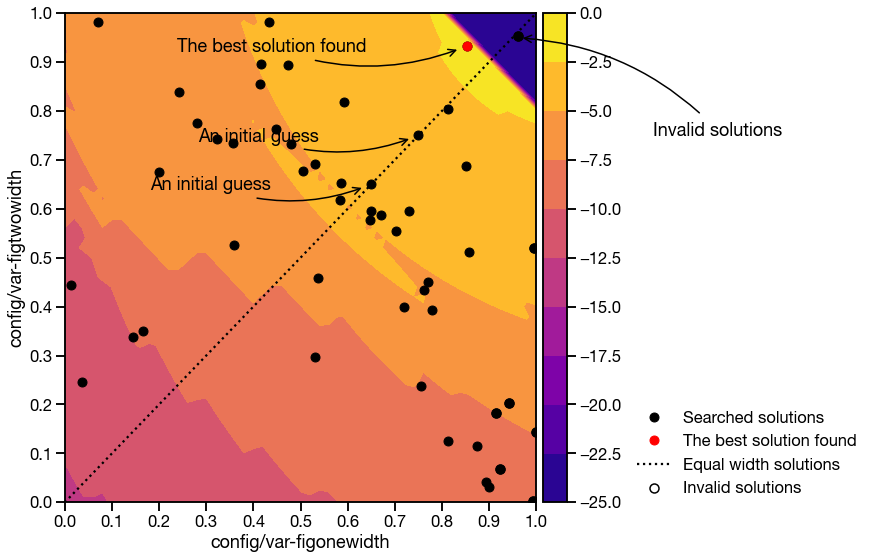
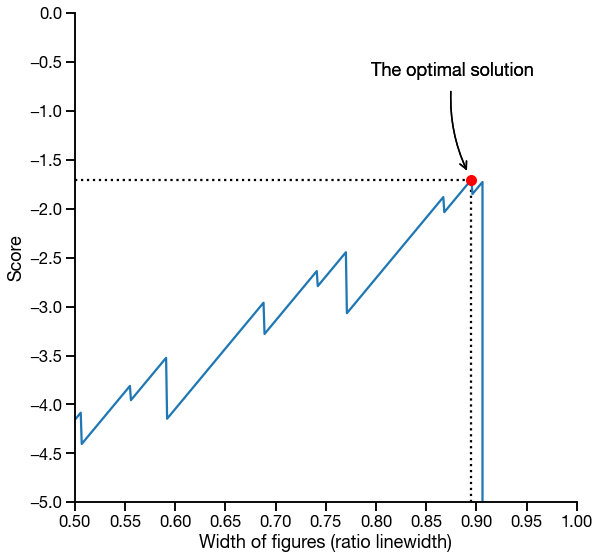

{kind=link}